

作为一家超级独角兽公司,Databricks是基于云的大数据处理和机器学习平台,旨在帮企业更轻松地处理大规模数据及进行智能决策。Databricks所提供的数据湖屋技术结合了数据湖和数据库的优势,能有效消除用户组织内部的数据壁垒,使用户得到满足在互联网数据爆炸性增长的背景下,对结构化、非结构化等多样化数据实时处理的需求。如今,Databricks已发展为一个更广泛的湖仓一体式的Databricks Marketplace,倍受数据工程师和数据科学家的关注与青睐。
为了让更多用户使用Spark,创始团队选择将其开源,于是Databricks应运而生。作为Apache Spark的核心要素,Databrick具有绝对的影响力、理解力和解释力,这也是其核心竞争力之一。
2016年,微软和Databricks达成合作。2017年11月,微软正式公开宣布将Databricks作为Azure的第一方服务平台,这在某种程度上预示着用户能在Azure门户中启动Databricks,Databricks用户也能轻松访问Azure上的功能,与所有其他Azure服务进行深度集成,从而构建现代数据分析通道。与微软的合作是Databricks的里程碑,这帮助其收入从2017年初的不到100万美元增长到2018年的超过1亿美元。
2018年,Databricks发布了MLflow来管理机器学习项目,一年后又发布了Delta Lake,二者均获得了市场认可。2020年6月,Databricks宣布收购以色列初创公司Redash并基于其技术推出了数据湖屋关键开源技术Delta Engine,可在Delta Lake之上分层以提高查询性能。同年11月,Databricks推出了Databricks SQL(以前称为SQL Analytics),用于在数据湖上运行商业智能和分析报告。
2021年,Databricks和谷歌云建立合作,使用户能在谷歌云上应用Databricks平台的功能。通过此次合作,Databricks成为了唯一一个可以在三大云平台(谷歌、亚马逊和微软)上使用的统一数据平台。同年10月,Databricks收购了德国无代码公司8080Labs,降低了平台的使用门槛,并在CIDR 2021发表论文首次正式提出了数据湖屋(Lakehouse)的概念。到2022年8月,Databricks的年营收已超过10亿美元。
2023年,为了应对OpenAI的ChatGPT, Databricks推出了开源语言模型Dolly。该模型使用更少的参数便可产生与ChatGPT类似的结果,研发人员可以使用它来创建自己的聊天机器人。同时,为了进一步增强公司实力,Databricks先后收购了数据安全公司Okera、人工智能公司MosaicML以及数据复制公司Arcion。2024年3月,Databricks推出通用大语言模型DBRX,号称是目前最强的开源AI,据称在各种基准测试中都超越了市面上所有的开源模型。
如今,Databricks在世界各地都设有办事处,客户遍布全球,包括荷兰银行(ABN AMRO)、康德纳仕(condnast)、Regeneron和壳牌(Shell)在内的全球9000多家组织机构。
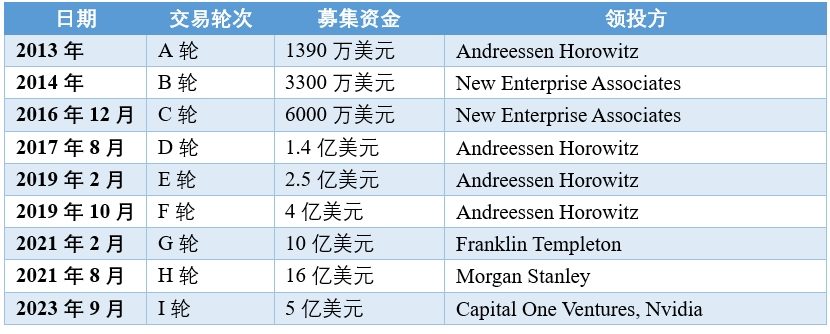
2021年2月,Databricks完成了10亿美元G轮融资,由Franklin Templeton领投,进一步巩固了其作为全球最有价值初创公司之一的地位。同年8月,Databricks又完成了16亿美元的H轮融资,公司估值被推至380亿美元。
截至目前,Databricks共完成了9轮融资,筹集资金42亿美元。如今随着融资放缓,许多处于后期阶段的初创公司的估值正在大幅下降,而Databricks在2023年9月I轮融资中的估值达到了430亿美元,较2021年融资后估值上升了50亿美元。
正如Databricks官网所示的Your data. Your AI. Your future. Own them all on the new data intelligence platform.,其业务集中在大数据和人工智能领域。Databricks致力于提供统一的数据分析平台,帮助企业加速数据处理、机器学习和人工智能工作流程,提升数据团队的效率和创新能力。其平台结合了数据工程、数据科学和数据团队协作的功能,以便用户可以在一个集成的环境中完成数据处理、分析和建模工作。
Databricks目标客户通常是拥有大量数据并需要先进分析和机器学习能力的大型企业组织。这些客户通常来自金融、医疗保健、零售和科技等行业,对快速高效地处理和分析大量数据有极为旺盛的需求。在这个过程中,他们可能面临着一系列技术上、法律上、伦理上的问题,如数据隐私和安全性问题,而这些都可以在Databricks获得较好的解决办法。
Databricks和Linux基金会联合开发了Delta Sharing数据共享平台,为跨数据、分析和人工智能的数据共享提供了一个开源方法。客户可以在高度安全和治理的平台区域之间共享实时数据,可以在企业内部业务线B分享与数据货币化等场景中应用。
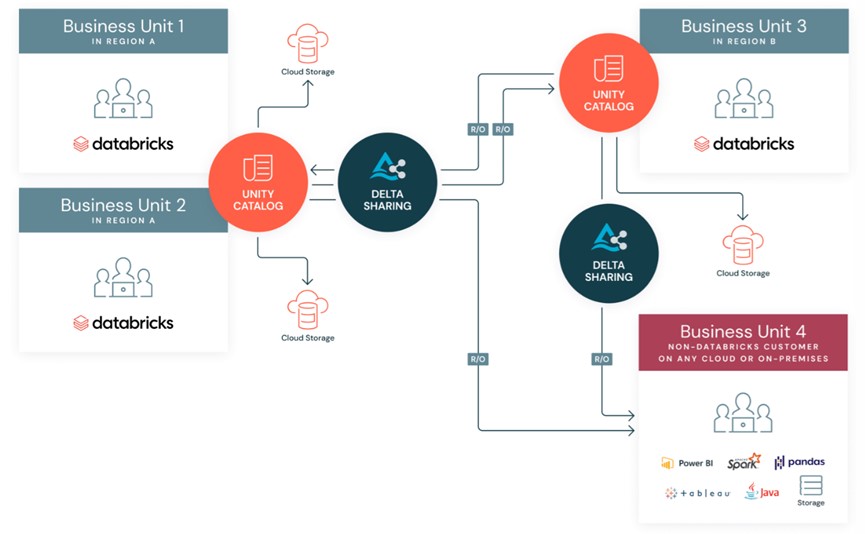
Databricks Unity Catalog为Databricks数据智能平台内的数据和人工智能提供了统一的管理方法。使用Unity Catalog,组织可以在任何云或平台上无缝地管理其结构化和非结构化数据、机器学习模型、笔记本、仪表板和文件。数据科学家、分析师和工程师能够正常的使用Unity Catalog发现、访问可信数据和人工智能资产并进行协作,利用人工智能提高生产力并释放数据湖屋架构的全部潜力。该功能能够提高生产力,简化许可模型,进行人工智能监控并提高可视性。
Databricks Mosaic AI能够提供统一的工具来构建、部署和监控人工智能和机器学习解决方案,包括构建预测模型、最新的GenAI和大型语言模型。基于Databricks数据智能平台,Mosaic AI使组织能够安全且经济高效地将企业数据集成到AI生命周期中。在保证企业对模型和数据的所有权的同时,提供准确、安全和可控的AI应用程序,并以更低的成本为用户培训定制化的大语言模型。
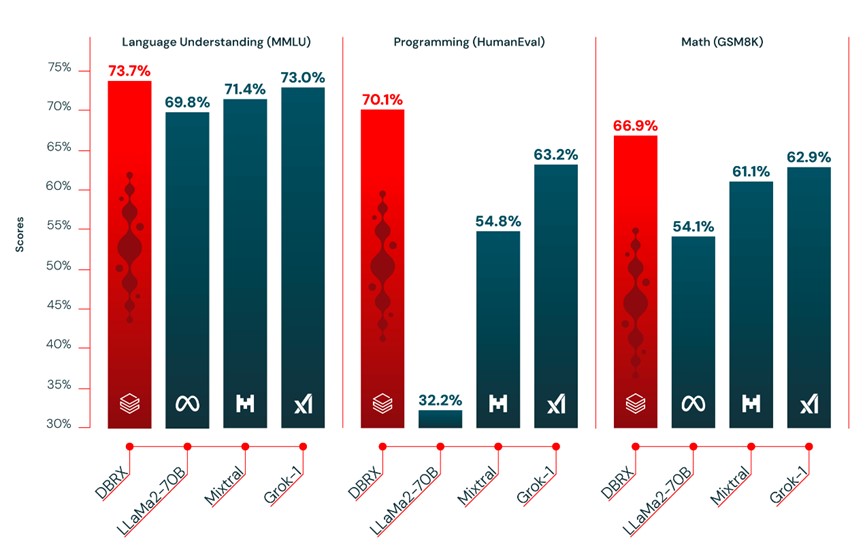
DBRX是Databricks下一代GenAI产品的核心支柱。它是由Databricks创建的开放的通用大语言模型,采用了创新的先进技术。此外,它为开放社区和企业提供了构建定制化大语言模型的功能,可供Databricks客户通过应用程序接口使用。根据Databricks的测试,它超过了GPT-3.5,与Gemini 1.0 Pro有相似的竞争力。另外,DBRX在开放模型中提高了效率,是同类型的模型计算速度的2倍。
Delta Lake是DataBricks公司开源的、用于构建数据湖屋架构的存储框架,是可以在开放格式之间自动即时转换的开放格式存储层,能够支持Spark、Flink、Hive、PrestoDB、Trino等查询计算引擎。
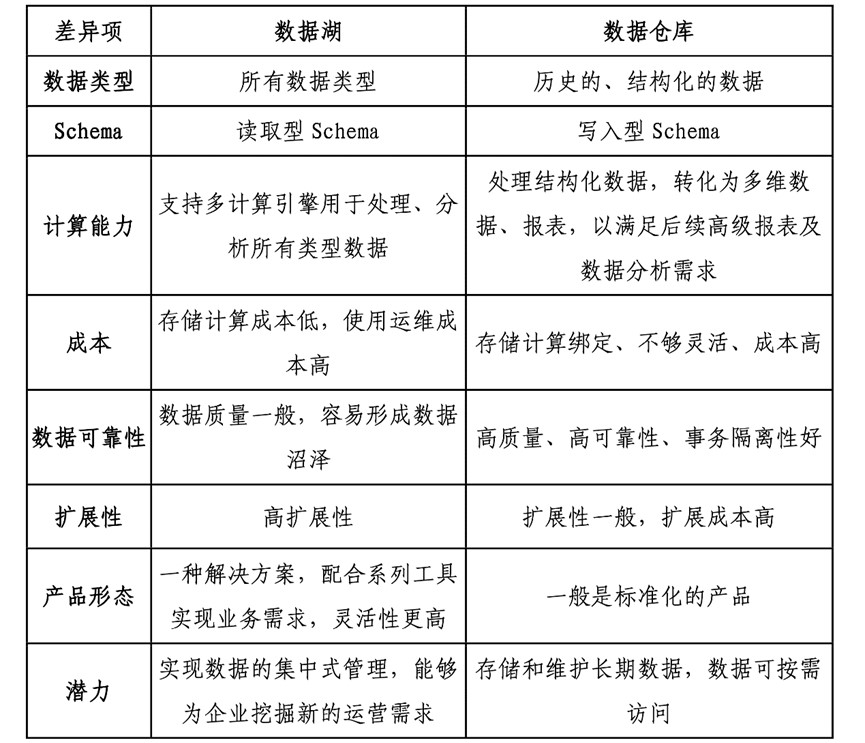
数据湖和数据库、数据仓库一样,都是数据存储的设计模式。区别在于,数据库和数据仓库通常采用明确的模式设计,即先定义好数据模型和数据结构,再将数据整合到这个模型中,因此数据库和数据仓库更固定、更静态;而数据湖则更注重数据的采集和存储,采用更灵活的架构对各种异构的数据源和数据格式进行处理,因此数据湖更加动态和灵活。数据湖屋结合了两者的优势,并且通过打通数据湖和数据仓库,能有效消除用户组织内部的数据壁垒。
Databricks数据智能平台极大地简化了数据流,在一个平台上提供实时分析、机器学习和应用程序。Data Streaming能够帮助用户使用已知的语言和工具构建数据平台,通过自动化构建和维护实时数据,简化开发和操作流程,并通过流的方式批量处理数据,消除数据孤岛。
Spark结构化流是实现Databricks数据智能平台上数据流的核心技术,为批处理和流处理提供统一的应用程序接口。Databricks是运行Apache Spark工作负载的最佳场所,其托管服务能够达到99.95%的正常运行率。
MLflow是一个能够覆盖机器学习全流程(从数据准备到模型训练到最终部署)的平台,旨在简化数据科学家构建、测试和部署机器学习模型的复杂过程。MLflow的第一个alpha版本有三个组件,其中跟踪组件(Tracking)支持记录和查询实验周围的数据,如评估指标和参数;项目组件(Projects)提供了可重复运行的简单包装格式;模型组件(Models)提供了管理和部署模型的工具。
与典型的开源商业模式有所不同,Databricks是一家站在云巨头肩膀上的公司,其盈利模式依托独特的SaaS开源模式进行。
Databricks本身是开源软件,通过提供附加功能进行收费,包括在开发、软件运行、运营和托管等方面。SaaS开源的盈利模式,支持客户在本地开源平台下载免费的基础软件,同时也可以下载开源公司打造的其他付费版本。
付费模式方面,Databricks根据客户每秒消耗的计算资源量收费。为此,其使用了一种独创的DBU作为其标准化单位,工作负载消耗的DBU数量取决于多个指标,包括使用的计算资源、处理的数据量、区域、所处的分级定价层以及正在使用的服务类型等。此外,为了吸引用户,Databricks为用户提供了14天免费试用期。
Databricks在运营过程中坚持三个原则:云上全流程、不做数据仓库、不做定制化。这一举措使得公司的基础软件能够规模化,使公司人员的单位产出最大化。对于未来发展的计划,Databricks曾明确表示,公司会一直做SaaS,并且只做SaaS。
另外,SaaS租赁模式也为Databricks的知识产权提供了保护。公司最有价值的知识产权蕴藏在监控和管理云端软件的工具和技术中,而不是在它所赞助的软件项目中(这些项目是公开的),这样便避免了泄露的风险。
根据《财富商业洞察》公布的《2021-2028年大数据分析市场报告》,目前大量初创公司正在争夺全球大数据分析市场的份额,预计2028年将达到5497.3亿美元。根据资本流动趋势和观察到的客户需求,大数据分析市场中最热门的领域是数据仓库、数据湖、数据湖仓、数据网格、DataOps和超快速大数据查询引擎。
随着互联网、物联网和各种传感器的普及,企业获得的数据来源更加庞大及多样化,包括结构化数据(如数据库中的表格数据)、半结构化数据(如XML、JSON等格式)和非结构化数据(如文本、图像、视频等)。一方面,企业需要高性价比的储存方案。随着云存储成本下降和网速提升,企业越来越多地选择将所有数据存储在中央存储库,而不是将不同的数据类型单独存储。另一方面,企业希望通过处理这些不同类型的数据,以获取有价值的信息。同时许多企业还有实时数据处理的需求,以便及时采取行动。例如,金融领域需要实时监控交易数据和市场波动,制造业需要实时监控设备状态和生产过程等。这种实时数据处理需求推动了实时数据处理技术的发展。数据处理需求快速增长,需求推送发展,大数据行业的体量在可预见的未来将会继续膨胀。
与此同时,基于海量的数据,企业希望利用人工智能技术来进行更加智能化的决策支持,如通过分析大数据来预测客户行为、优化供应链、改善产品设计等;或者提供个性化的产品和服务,如通过分析用户的行为和偏好来推荐相关产品、个性化定价、个性化营销等。这种个性化服务可以提升用户满意度和忠诚度。AI的辅助可以帮企业降本增效,并获得竞争优势。
大数据和人工智能行业未来预期可观,竞争也明显地加剧。Databricks目前的发展主要面临三类对手的夹击。
第一类对手是同一行业的其他云数据平台。2012年,前Oracle架构师创立的Snowflake是Databricks不可忽视的对手。最初,Snowflake将自己定位为提供数据仓和分析计算工作负载的云数据平台,主要面向业务分析师和数据工程师等用户。同期的Databricks则一直受数据科学家和机器学习工程师的青睐。
但现在二者的界限正在模糊,比如Snowflake发布了Snowpark for Data Science、事务数据库以及Python支持功能,希望以此吸引数据科学家。而Databricks则推出了Databricks SQL、Delta Lake功能和Unity Catalog等产品,以满足数据存储功能和注重数据安全的客户。从模式来看,Snowflake是闭源生态,而Databricks是开源的。Databricks的主要产品线都可以免费使用,当客户要获得更高级的功能和支持时,可以再一次进行选择相关付费产品。Snowflake提供现成的解决方案,使公司能快速开展基本分析,而Databricks提供更好的定制和配置,让客户能够完全控制他们的设置。
2022年底,Snowflake的年收入为21亿美元,但增速放缓;而Databricks预计年收入为14亿美元,但增速可观。预计未来两家的竞争会愈发激烈。
第三类竞争对手为特定领域的解决方案公司。Databricks与特定的数据管理和科学领域解决方案公司也存在竞争。比如Databricks的调度程序类似Apache Airflow,MLflow产品与DataRobot和Alteryx提供相似的服务。
今年来,Databricks被多名作家在旧金山联邦法院提起集体诉讼,称该公司在训练大模型时未经同意、未经认可、无补偿地复制和借鉴了他们的书籍。
根据起诉书,Databricks被指控分别使用盗版数字电子书库Books3的数据训练了公司旗下的大模型MosaicML。在训练期间,大模型复制并摄取训练数据集中的每个文本作品,并从中提取受保护的表达。原告认为,Databricks收购了MosaicML公司,而MosaicML生产MPT系列大型语言模型中使用了含有盗版内容的数据集进行训练,因此构成著作权侵权。一同被指控的还有英伟达旗下的大模型NeMo Megatron。
人工智能工具的繁荣正在考验版权法的边界,内容创作者和AI间的版权之争愈演愈烈。到底是侵犯版权还是合理使用,目前还没明确的答案。美媒Vox指出,一方面,技术创新的倡导者认为,人工智能技术充满了希望,建议还是不要为了过度保护版权而牺牲人工智能训练的效率。另一方面,媒体及内容创作者认为,即使是颠覆行业的科技公司在使用受版权保护的内容时也需要付费。